АСЦИИ кодирање. АСЦИИ табела кодирања
Ундер информације о кодирању у компјутеру, подразумева се процес његовог претварања у форму, што омогућава организовање прикладнијег преноса, складиштења или аутоматске обраде ових података. У ту сврху користе се различите табеле. АСЦИИ кодирање је први систем развијен у Сједињеним Америчким Државама да ради са текстом на енглеском језику, који је касније дистрибуиран широм света. Његов опис, карактеристике, својства и даља употреба чланка приказани су у наставку.
Приказ и чување информација у рачунару
Симболи на компјутерском монитору или мобилном дигиталном гадгету формирају се на основу скупова векторских облика различитих знакова и кода, који омогућују да се међу њима пронађе лик који треба уметнути на право мјесто. То је низ битова. Дакле, сваки симбол мора недвосмислено одговарати скупу нула и оних који стоје у одређеном, јединственом поретку.
Ad
Како је све почело
Историјски, први компјутери су били енглески. Да би се кодирале информације о њима, било је довољно користити само 7 битова меморије, док је за ову сврху додељен 1 бајт, који се састоји од 8 бита. Број знакова које је рачунар схватио у овом случају био је 128. Ови знакови су укључивали енглеску абецеду са својим знаковима интерпункције, бројевима, а неке специјални знакови. Енглеско седмо-битно кодирање са одговарајућом табелом (кодна страница), развијено 1963. године, названо је Америцан Стандард Цоде фор Информатион Интерцханге. Обично је за своју ознаку коришћена и још увек се користи скраћеница „АСЦИИ Цодинг“.
Ad
Прелазак на вишејезичност
Временом су рачунари почели да се широко користе у земљама које не говоре енглески. У том смислу, постоји потреба за кодирањем које дозвољава употребу националних језика. Одлучено је да се не изнова проналази точак и АСЦИИ као основа. Табела кодирања у новом издању значајно се проширила. Употребом осмог бита дозвољено је превести 256 знакова у компјутерски језик.
Десцриптион
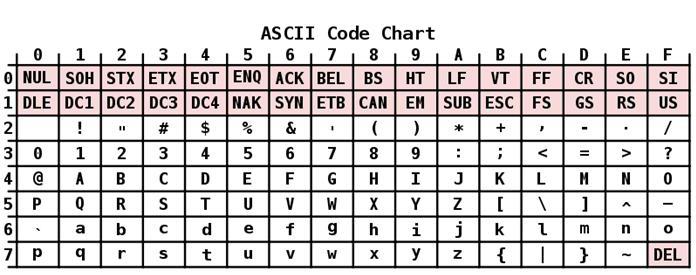
АСЦИИ кодирање има табелу која је подељена на 2 дела. Сматра се да је општеприхваћени међународни стандард само његова прва половина. То укључује:
- Знакови са редним бројевима од 0 до 31, кодирани секвенцама од 00000000 до 00011111. Они су резервисани за контролне знакове који контролишу процес приказивања текста на екрану или штампачу, бип, итд.
- Знакови са НН у табели од 32 до 127, кодирани секвенцама од 00100000 до 01111111 чине стандардни део табеле. То укључује размак (Н 32), латинична слова (мала и велика слова), десет-знаменкасти број од 0 до 9, знакове интерпункције, заграде различитих врста и друге знакове.
- Ликови са редним бројевима од 128 до 255, кодирани по секвенцама од 10,000,000 до 1100. Они укључују слова националних писама осим латинице. Овај алтернативни део табеле је АСЦИИ кодирање које се користи за конвертовање руских знакова у рачунарску форму.
Нека својства
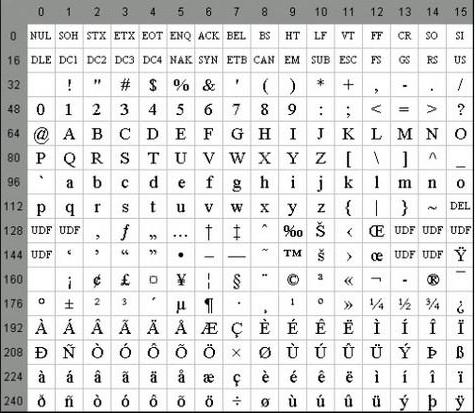
Посебне карактеристике АСЦИИ кодирања су разлика између слова "А" - "З" доњег и горњег регистра са само једним битом. Ова околност знатно поједностављује конверзију регистра, као и његову верификацију припадности датом опсегу вредности. Поред тога, сва слова у АСЦИИ систему кодирања су представљена сопственим серијским бројевима у абецеди, који се у бинарном бројевном систему пишу у 5 цифара, а за мала слова 011, а горњи за 010 2 .
Ad
Међу карактеристикама кодирања АСЦИИ се може рачунати и приказати 10 цифара - "0" - "9". У другом систему бројева, они почињу са 00112, а завршавају са 2 броја. Дакле, 0101 2 је еквивалентан децималном броју од пет, тако да се знак "5" пише као 0011 01012. На основу горе наведеног, можете лако претворити бинарно-децималне бројеве у АСЦИИ низ додавањем битне секвенце 00112 на свако грицкање на лијево.

"Уницоде"
Као што знате, за приказивање текстова на језицима групе југоисточне Азије, потребно је на хиљаде знакова. Овакав број њих није ни на који начин описан у једном бајту информација, тако да чак и проширене верзије АСЦИИ више не могу задовољити растуће потребе корисника из различитих земаља.
Тако је постало неопходно креирати универзално кодирање текста, чији је развој, у сарадњи са многим лидерима глобалне ИТ индустрије, преузет од стране Уницоде конзорцијума. Његови специјалисти креирали су УТФ 32 систем, ау њему је додељено 32 бита за кодирање 1 знака, који чине 4 бајта информација. Главни недостатак био је оштар пораст количине потребне меморије за чак 4 пута, што је изазвало многе проблеме.
Ad
Истовремено, за већину земаља са званичним језицима који припадају индоевропској групи, број знакова једнаких 2 32 је више него претеран.
Као резултат даљег рада стручњака из Уницоде конзорцијума, појавио се УТФ-16 кодирање. Постала је опција претварања симболичких информација, које су за све уређивале и по количини потребне меморије иу смислу броја кодираних знакова. Зато је УТФ-16 усвојен по дефаулту и захтијева 2 бајта да буду резервисана за један знак.
Чак и ова прилично напредна и успјешна верзија Уницода-а имала је неке недостатке, а након пребацивања са проширене верзије АСЦИИ-а на УТФ-16, удвостручила је тежину документа.
У том смислу, одлучено је да се користи кодирање променљиве дужине УТФ-8. У овом случају, сваки знак у изворном тексту је кодиран у дужини од 1 до 6 бајтова.

Обратите се америчком стандардном коду за размјену информација
Сви знакови латиница у УТФ-8 променљивој дужини кодираној у 1 бајт, као у АСЦИИ систему кодирања.
Посебна карактеристика УТФ-8 је да у случају текста на латинском без употребе других знакова, чак и програми који не разумију Уницоде ће и даље дозволити да се прочита. Другим речима, основни део кодирања АСЦИИ текста се једноставно преноси на нову УТФ променљиву дужину. Ћирилични знакови у УТФ-8 заузимају 2 бајта, и, на пример, грузијски - 3 бајта. Креирањем УТФ-16 и 8, ријешен је главни проблем стварања јединственог простора кода у фонтовима. Од тада, произвођачи фонтова морају само да попуне табелу са векторским облицима текстуалних симбола на основу њихових потреба.
Ad
У различитим оперативним системима, предност се даје различитим кодирањима. Да би могли да читају и уређују текстове уписане у другачијем кодирању, користе се руски програми за конверзију текста. Неки текстуални уређивачи садрже уграђене транскодере и омогућавају читање текста без обзира на кодирање.

Сада знате колико је знакова у АСЦИИ и како и зашто је развијено. Наравно, данас је Уницоде стандард постао најраспрострањенији у свету. Међутим, не смијемо заборавити да је креиран на бази АСЦИИ-а, па бисте требали цијенити допринос својих програмера у области ИТ-а.